上文已实现了简单的抓取文章的功能,这里进一步改进
修改scrapytutorial目录的items.py文件
1 | import scrapy |
修改spiders目录blog_spider.py文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import scrapy
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
from ..items import ScrapytutorialItem
class BlogSpider(scrapy.Spider):
name = 'blog'
start_urls = {
'https://www.cnblogs.com/chenying99/'
}
def parse(self, response):
items = ScrapytutorialItem()
container = response.css('#main')[0]
posts = container.css('div.post')
for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip()
link = article.css('a.postTitle2::attr(href)').extract_first()
items['title'] = title
items['link'] = link
yield items
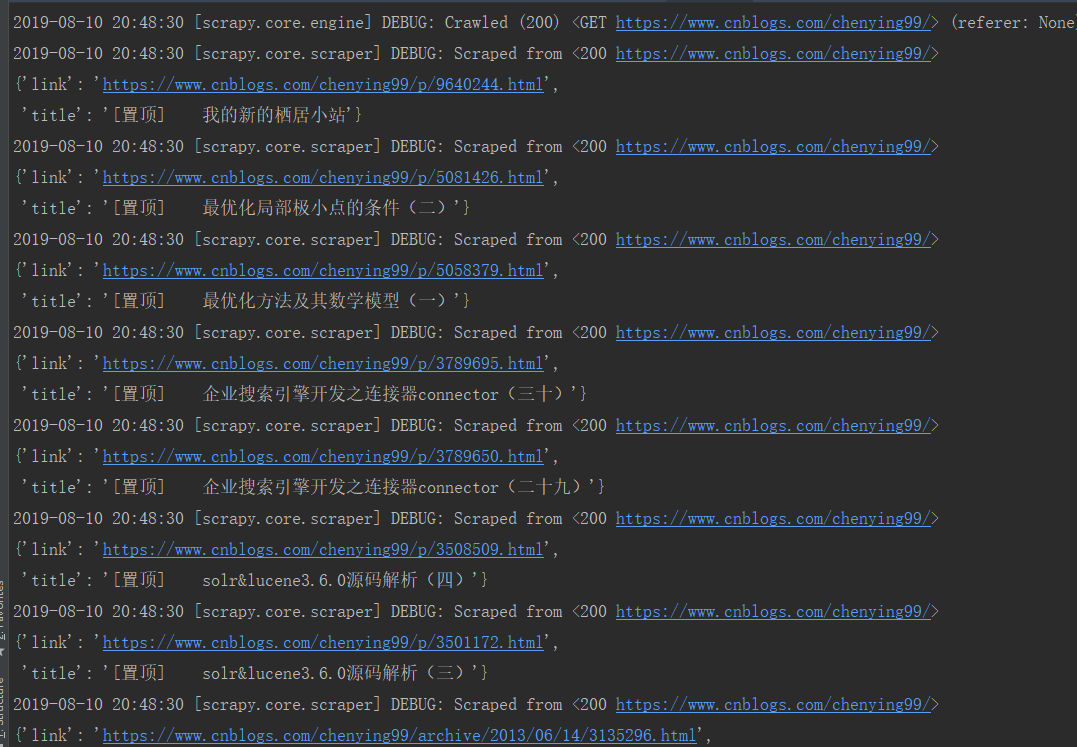
重新运行scrapy crawl blog