也可以将scrapy采集的数据输出到json文件,运行scrapy crawl blog -o items.json
本文主要介绍怎样将采集的数据存储到mongodb
首先配置setting.py文件里面的item pipelines
1 | # Configure item pipelines |
安装pymongo
conda install pymongo
修改pipelines.py文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import pymongo
class ScrapytutorialPipeline(object):
def __init__(self):
self.conn = pymongo.MongoClient(
'127.0.0.1',
27017
)
db = self.conn['scrapy']
self.collection = db['blog']
def process_item(self, item, spider):
# print("pipline测试 "+item['title'])
self.collection.insert(dict(item))
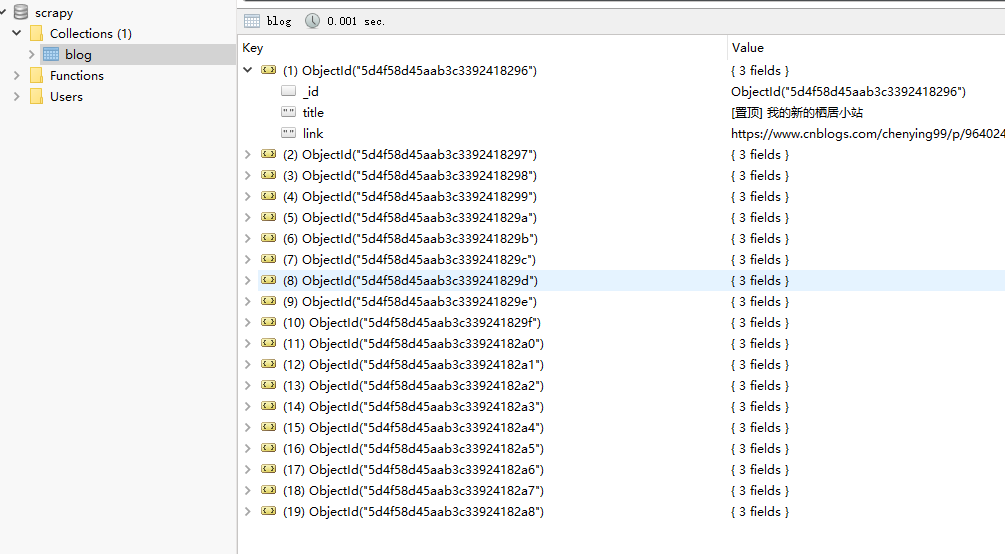
运行scrapy crawl blog
查看mongodb数据库记录