opencv是一个图像处理包,貌似是用C++开发的,本系列则基于python语言,底层调用c++版本的opencv
opencv环境安装
conda install opencv-python
(貌似自动安装了相关依赖numpy)
opencv是一个图像处理包,貌似是用C++开发的,本系列则基于python语言,底层调用c++版本的opencv
opencv环境安装
conda install opencv-python
(貌似自动安装了相关依赖numpy)
scikit-learn是一个python版的机器学习库,它依赖于numpy scipy matplotlib等
其中numpy封装了矩阵相关数据结构及其操作,scipy封装了最优化、数值积分、线性代数等相关模块,matplotlib貌似是一个绘图工具
而scikit-learn作为机器学习库,依赖于上面这些功能模块
首先需要安装环境:
conda install scikit-learn
上面的命令会自动安装相关依赖(numpy scipy)
conda install matplotlib
本文实现用户登录功能
1 | import scrapy |
补充:
调试scrapy爬虫
scrapytutorial/scrapytutorial目录,新建run.py文件1
2
3
4
5
6from scrapy import cmdline
name = 'quotes'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
安装scrapy-user-agents
conda install scrapy-user-agents
setting.py文件添加1
2
3
4DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy_user_agents.middlewares.RandomUserAgentMiddleware': 400,
}
安装scrapy-proxy-pool
conda install scrapy-proxy-pool
setting.py文件添加1
2
3
4
5
6
7
8PROXY_POOL_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
# ...
'scrapy_proxy_pool.middlewares.ProxyPoolMiddleware': 610,
'scrapy_proxy_pool.middlewares.BanDetectionMiddleware': 620,
# ...
}
本文实现详情页数据的采集功能
首先修改items.py文件,新增ArticleItem类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import scrapy
class ScrapytutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
# pass
class ArticleItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
content = scrapy.Field()
update = scrapy.Field()
cate = scrapy.Field()
修改blog_spider.py文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46import scrapy
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
from ..items import ScrapytutorialItem
from ..items import ArticleItem
class BlogSpider(scrapy.Spider):
name = 'blog'
start_urls = {
'https://www.cnblogs.com/chenying99'
}
def parse(self, response):
items = ScrapytutorialItem()
container = response.css('#main')[0]
posts = container.css('div.post')
for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip()
link = article.css('a.postTitle2::attr(href)').extract_first()
items['title'] = title
items['link'] = link
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse_details)
next_page = response.css('#homepage_bottom_pager > div > a:nth-child(8)::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
def parse_details(self, response):
items = ArticleItem()
title = response.css('#cb_post_title_url::text').extract_first(default='not-found').strip()
link = response.css('#cb_post_title_url::attr(href)').extract_first().strip()
content = response.css('#cnblogs_post_body').extract_first().strip()
cate = response.css('#BlogPostCategory > a::text').get(default='not-found')
update = response.css('#post-date::text').extract_first().strip()
items['title'] = title
items['link'] = link
items['content'] = content
items['cate'] = cate
items['update'] = update
yield items
修改pipelines.py文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import pymongo
from .items import ArticleItem
class ScrapytutorialPipeline(object):
def __init__(self):
self.conn = pymongo.MongoClient(
'127.0.0.1',
27017
)
db = self.conn['scrapy']
self.collection = db['article']
def process_item(self, item, spider):
if isinstance(item, ArticleItem):
return self.collection.insert(dict(item))
return item
本文实现scrapy的分页采集功能
分页方式一:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import scrapy
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
from ..items import ScrapytutorialItem
class BlogSpider(scrapy.Spider):
name = 'blog'
start_urls = {
'https://www.cnblogs.com/chenying99/'
}
def parse(self, response):
items = ScrapytutorialItem()
container = response.css('#main')[0]
posts = container.css('div.post')
for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip()
link = article.css('a.postTitle2::attr(href)').extract_first()
items['title'] = title
items['link'] = link
yield items
next_page = response.css('#homepage_bottom_pager > div > a:nth-child(8)::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
分页方式二:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import scrapy
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
from ..items import ScrapytutorialItem
class BlogSpider(scrapy.Spider):
name = 'blog'
page_number = 2
start_urls = {
'https://www.cnblogs.com/chenying99/default.html?page=1'
}
def parse(self, response):
items = ScrapytutorialItem()
container = response.css('#main')[0]
posts = container.css('div.post')
for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip()
link = article.css('a.postTitle2::attr(href)').extract_first()
items['title'] = title
items['link'] = link
yield items
next_page = 'https://www.cnblogs.com/chenying99/default.html?page='+str(BlogSpider.page_number)
if BlogSpider.page_number < 10:
BlogSpider.page_number += 1
yield response.follow(next_page, callback=self.parse)
也可以将scrapy采集的数据输出到json文件,运行scrapy crawl blog -o items.json
本文主要介绍怎样将采集的数据存储到mongodb
首先配置setting.py文件里面的item pipelines
1 | # Configure item pipelines |
安装pymongo
conda install pymongo
修改pipelines.py文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import pymongo
class ScrapytutorialPipeline(object):
def __init__(self):
self.conn = pymongo.MongoClient(
'127.0.0.1',
27017
)
db = self.conn['scrapy']
self.collection = db['blog']
def process_item(self, item, spider):
# print("pipline测试 "+item['title'])
self.collection.insert(dict(item))
运行scrapy crawl blog
查看mongodb数据库记录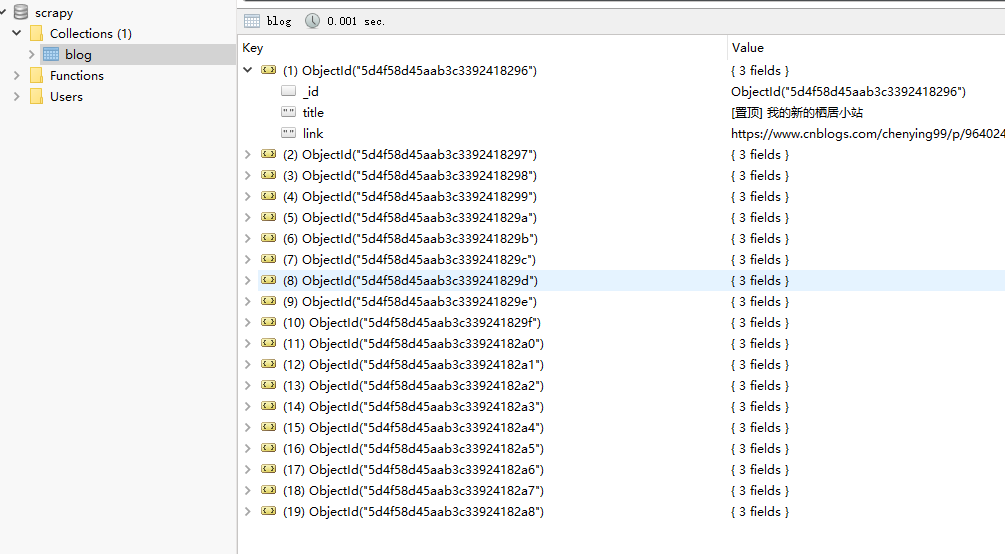
上文已实现了简单的抓取文章的功能,这里进一步改进
修改scrapytutorial目录的items.py文件
1 | import scrapy |
修改spiders目录blog_spider.py文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import scrapy
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
from ..items import ScrapytutorialItem
class BlogSpider(scrapy.Spider):
name = 'blog'
start_urls = {
'https://www.cnblogs.com/chenying99/'
}
def parse(self, response):
items = ScrapytutorialItem()
container = response.css('#main')[0]
posts = container.css('div.post')
for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip()
link = article.css('a.postTitle2::attr(href)').extract_first()
items['title'] = title
items['link'] = link
yield items
重新运行scrapy crawl blog
修改scrapytutorial目录settings.py文件
USER_AGENT = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36’
这里以抓取博客园文章为例
在spiders目录添加blog_spider.py文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import scrapy
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
class BlogSpider(scrapy.Spider):
name = 'blog'
start_urls = {
'https://www.cnblogs.com/chenying99/'
}
def parse(self, response):
container = response.css('#main')[0]
posts = container.css('div.post')
for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip()
link = article.css('a.postTitle2::attr(href)').extract_first()
yield {'标题': title, '链接': link}
运行scrapy crawl blog
补充:获取html标签的css选择器,SelectorGadget plugin
创建环境
conda create –name scrapytutorial python=3.7.4
安装scrapy
conda install -c scrapinghub scrapy
创建项目
scrapy startproject scrapytutorial
生成的项目如下