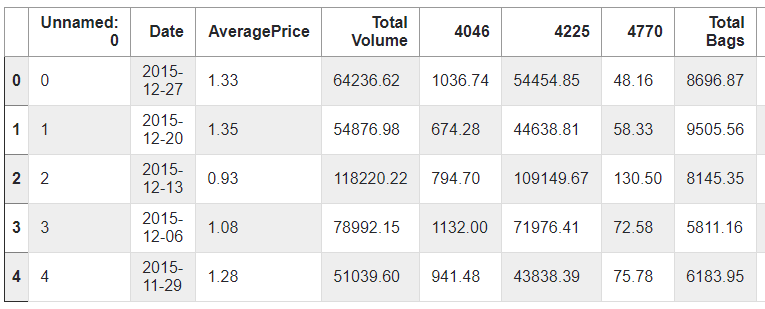
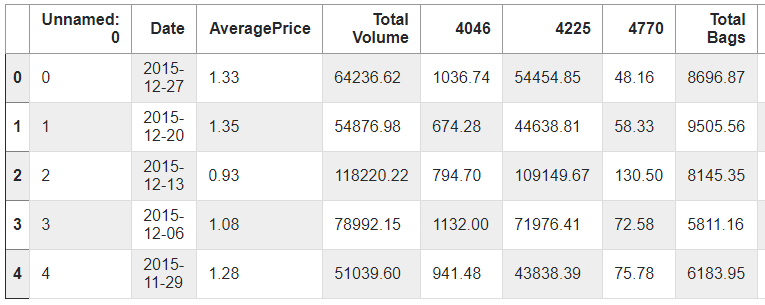
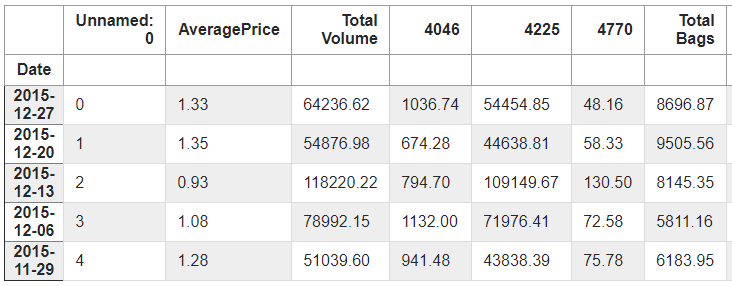
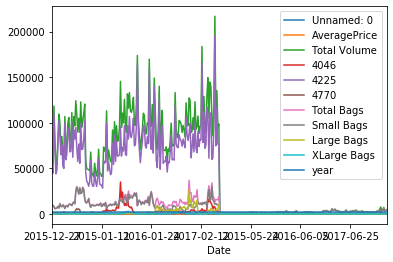
classScrapytutorialItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() link = scrapy.Field() # pass
classArticleItem(scrapy.Item): title = scrapy.Field() link = scrapy.Field() content = scrapy.Field() update = scrapy.Field() cate = scrapy.Field()
items = ScrapytutorialItem() container = response.css('#main')[0] posts = container.css('div.post') for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip() link = article.css('a.postTitle2::attr(href)').extract_first() items['title'] = title items['link'] = link url = response.urljoin(link) yield scrapy.Request(url=url, callback=self.parse_details)
next_page = response.css('#homepage_bottom_pager > div > a:nth-child(8)::attr(href)').get() if next_page isnotNone: yield response.follow(next_page, callback=self.parse)
defparse_details(self, response): items = ArticleItem() title = response.css('#cb_post_title_url::text').extract_first(default='not-found').strip() link = response.css('#cb_post_title_url::attr(href)').extract_first().strip() content = response.css('#cnblogs_post_body').extract_first().strip() cate = response.css('#BlogPostCategory > a::text').get(default='not-found')
update = response.css('#post-date::text').extract_first().strip() items['title'] = title items['link'] = link items['content'] = content items['cate'] = cate items['update'] = update yield items
items = ScrapytutorialItem() container = response.css('#main')[0] posts = container.css('div.post') for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip() link = article.css('a.postTitle2::attr(href)').extract_first() items['title'] = title items['link'] = link yield items next_page = response.css('#homepage_bottom_pager > div > a:nth-child(8)::attr(href)').get() if next_page isnotNone: yield response.follow(next_page, callback=self.parse)
items = ScrapytutorialItem() container = response.css('#main')[0] posts = container.css('div.post') for article in posts:
title = article.css('a.postTitle2::text').extract_first().strip() link = article.css('a.postTitle2::attr(href)').extract_first() items['title'] = title items['link'] = link yield items